Do not `panic!`
The following is the written version of my talk at the Budapest Rust Meetup. If you want to check out the slides, you can find them here.
Introduction

Errors in software are seemingly ubiquitous - we see them a lot both as users and as engineers. As users, we can only get angry at our favourite streaming website not loading, but as developers, we bear all the responsibility to make sure that that exact thing does not happen. However, accomplishing this is far easier said than done. For example, imagine you’re tasked to work on the following code - do you have any idea what could go wrong during the order process by just taking a cursory glance?
app.post('/orders', async (req, res) => {
const user = await fetchUser(req.userId);
const items = await orderProducts(req.body.products);
const invoice = await generateInvoice(items);
return {
paymentUrl: buildPaymentUrl(invoice),
};
});In JS, every function can throw arbitrary values, so there’s no way to know without looking through all functions to find out what failure modes are available. (Or the docs tell us exactly what kind of error is thrown when - one can dream…).
How does this work in other languages? Let’s take a short tour below.
In C++, the situation is similar, we really have no idea whether something can throw or not (except for the throws and noexcept mechanisms, but the first is discouraged, the second is only for enabling specific optimizations by the compiler):
user fetch_user(std::string_view user_id);C#, being similar to C++, also doesn’t help:
class UserService { public async Task<User> fetchUser(String userId); }Even TypeScript doesn’t really offer a solution here:
async function fetchUser(userId: string): User;Java is very interesting here, as it offers some insight as to what errors a specific methods can throw - but it’s not the complete picture, as RuntimeExceptions don’t need to be listed in the method signature:
class UserService {
public User fetchUser(String userId) throws NonExistentEntityException;
}All in all, we can deduce that error handling is quite hard to get right! The main issue stems from the fact that we need to deal with known & unknown unknowns, which can bring lots of complexity to even a simpler application, especially when a combination of things go wrong at once.
How Does Rust Fare In This Regard?
Rust promises us lots of things, for example:
- Blazingly (🔥) fast™ performance,
- Memory efficiency,
- Memory-safety, thread-safety,
- A strong, rich type system,
- A very strict compiler.
But what about its error handling strategies? The rest of this article will examine how Rust error handling works, and shows how to make use of it to its fullest extent in order to get the best user experience possible.
Goals of Error Handling
Before diving deep, let’s first define what the main goals of error handling are, so that we’re all aligned on the fundamentals. In my point of view, error handling has 2 very distinct objectives:
User Feedback:
- Tell the user that something went wrong,
- Offer ideas on how to fix it, if it is a user error (ex. providing an invalid input).
Troubleshooting:
- Provide as much info to the operator as possible so they can identify the fault and severity swiftly,
- Make debugging simple so the issue can be rectified quickly from the engineers’ side.
We’ll see how these aspects play out with the different error handling mechanisms Rust provides in the next 2 chapters.
Unrecoverable Errors :: panics
The first type of error handling mechanism offered by Rust is something called a panic. A panic is an easy and quick way to terminate execution of a program if something that shouldn’t happen happens. A little bit more nuance on this: actually, an unhandled panic doesn’t terminate the whole program, just the thread it occurred on - but, if that thread is the main thread, by default it’ll terminate the program with a 101 exit code.
The most important thing to remember about panics is that an unhandled one is 99% a bug in the code! For example, it’s not great to panic on invalid user input it a CLI, or when a validation error occurs in an HTTP server - in fact, that’d be very bad as then the TCP socket would just close abruptly without any response being returned to the caller!
panics are similar to C++ exceptions in the sense that when triggering one, the stack is unwound, and the drop method for all variables is called; though that is not guaranteed, and can be turned off completely for increased performance.
panicking with Macros
We can trigger a panic in many different ways in our program. First of all, let’s take a look at some macros that do it.
The panic! macro is the simplest - it takes a format string as argument and will display it as the panic message:
panic!("I'm panicking!");
// $ cargo run
// thread 'main' panicked at src/main.rs:2:3:
// I'm panicking!The todo! macro is good if you want to signify paths in your code that are being worked on, but you want your code to compile anyway.
let res = if n < 5 {
foo(n)
} else {
todo!("Will do next week")
};
// $ cargo run
// thread 'main' panicked at src/main.rs:2:3:
// not yet implemented: Will do next weekThe unimplemented! macro is similar, but it signals that the path is intentionally unimplemented.
let res = if n < 5 {
foo(n)
} else {
unimplemented!("Not needed for now")
};
// $ cargo run
// thread 'main' panicked at src/main.rs:2:3:
// not implemented: Not needed for nowThe unreachable! macro is helpful to signal to the Rust compiler that a given code path will never happen in case it’s not smart enough to figure it out (usually it is, so there are only a few cases when you need to reach for this).
match n /*: Option<i32> */ {
Some(n) if n >= 0 => println!("Some(Non-negative)"),
Some(n) if n < 0 => println!("Some(Negative)"),
Some(_) => unreachable!("Handled all ns already"), // <-- compile error if not here
None => println!("None"),
}
// $ cargo run
// thread 'main' panicked at src/main.rs:2:3:
// internal error: entered unreachable code: Handled all ns alreadyFor testing, we have some basic assertion macros that we can use - a test in Rust fails if it panics, and passes, if it executes without any panic.
assert_eq!(3, 4); // assertion `left == right` failed, left: 3, right: 4
assert!(3 == 4); // assertion failed: 3 == 4panicking with Functions
Next, let’s see the most important standard library functions that produce a panic.
The Option::unwrap function produces a panic with a generic message if the Option is None. Useful if you’re sure that the value exists:
let home_dir = home::home_dir().unwrap(); // home::home_dir() -> Option<PathBuf>
// $ cargo run
// thread 'main' panicked at src/main.rs:2:3:
// called `Option::unwrap()` on a `None` valueResult::unwrap is the same, but it’ll panic if the value is Err:
let contents = read_to_string("a.txt").unwrap(); // read_to_string(P) -> io::Result<String>
// $ cargo run
// thread 'main' panicked at src/main.rs:2:3:
// called `Result::unwrap()` on an `Err` value:
// Os { code: 2, kind: NotFound, message: "No such file or directory" }The Option::expect function is similar, but the caller can provide a custom message upon panicking:
let home_dir = home::home_dir().expect("User should have a home directory");
// $ cargo run
// thread 'main' panicked at src/main.rs:2:3:
// User should have a home directoryAnd we have one for Result as well:
let contents = read_to_string("a.txt").expect("File should exist");
// $ cargo run
// thread 'main' panicked at src/main.rs:2:3:
// File should exist:
// Os { code: 2, kind: NotFound, message: "No such file or directory" }The convention around using expect is to provide a message that explains what should be true when calling the function. For example, read_to_string("a.txt").expect("File should exist") reads as “I, as the author expect that the file should 100% exist at this point when executing the program”.
Writing Functions that panic
When using Rust, you’ll inevitably write some functions that can produce a panic - these are usually cases passing in certain values is obviously a caller error, and we don’t want to slow our function down to check whether all preconditions are met. In these occasions, always document with a doc comment in what conditions your function can produce a panic, like so:
/// # Panics
///
/// Will panic if `y` is `0`.
pub fn divide(x: i32, y: i32) -> i32 {
if y == 0 {
panic!("Cannot divide by 0")
} else {
x / y
}
}If you’re authoring a library, the missing_panics_doc clippy lint could be very useful to make sure that all panicking functions are marked in the documentation.
What panics in std?
Alongside of writing your own panicking functions, sometimes you’ll call ones from std which can produce a panic. Fortunately, the authors of these functions are nice and documented the panic conditions, so be sure to read the docs!
The main panicking function you’ll encounter in your day-to-day is the unchecked indexing operator of Vecs and HashMaps, which can be used get an element at a particular position/associated with a particular key. If said index is out of bounds/the key doesn’t exist, the function will panic, in order to save some processor instructions. If you want a version which’ll actually do the bounds/key existence check for you, call the get/get_mut functions instead, as they return an Option<&T>/Option<&mut T> instead!
fn main() {
let _val = Vec::<i32>::new()[1];
}
// $ cargo run
// thread 'main' panicked at src/main.rs:2:33:
// index out of bounds: the len is 0 but the index is 1Another interesting case where a function will panic is the arithmetic operators of numbers, which will not let numbers over-or underflow when running the app in debug mode. This means you’ll get a panic when one happens in development or during testing, but will allow over/underflow in release builds, for increased performance.
#[allow(arithmetic_overflow)] // Needed as the compiler is smart in this case
fn main() {
let _n = i32::MAX + i32::MAX;
}
// $ cargo run
// thread 'main' panicked at src/main.rs:2:22:
// attempt to add with overflowBacktraces
A task you sometimes need to do when working in Rust is debug why a particular panic occurred, so you can fix the root cause (remember, unhandled panics are 99% bugs in the code!). However, panics by default don’t help us in diagnosing how the execution got to the point where it blew up. For example, take a look at the following output:
$ cargo run
thread 'main' panicked at src/submodule-1/submodule-2/foo.rs:67842:583:
index out of bounds: the len is 10 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtraceWe can see that we at least get the filename and location where the panic occurred, along with the message, but nothing more - if the panic happened in a function used by lots of other components, it can be quite hard to figure out what exactly went wrong. However, our program already offers something interesting - it states that if we set the RUST_BACKTRACE environment variable to 1, then we get something that’s more helpful, so let’s try it:
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/submodule-1/submodule-2/foo.rs:67842:583:
index out of bounds: the len is 10 but the index is 10
stack backtrace:
0: rust_begin_unwind
at /rustc/25ef9e3d85d934b27d9dada2f9dd52b1dc63bb04/library/std/src/panicking.rs:647:5
1: core::panicking::panic_fmt
at /rustc/25ef9e3d85d934b27d9dada2f9dd52b1dc63bb04/library/core/src/panicking.rs:72:14
2: core::panicking::panic_bounds_check
at /rustc/25ef9e3d85d934b27d9dada2f9dd52b1dc63bb04/library/core/src/panicking.rs:208:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at /rustc/25ef9e3d85d934b27d9dada2f9dd52b1dc63bb04/library/core/src/slice/index.rs:255:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at /rustc/25ef9e3d85d934b27d9dada2f9dd52b1dc63bb04/library/core/src/slice/index.rs:18:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at /rustc/25ef9e3d85d934b27d9dada2f9dd52b1dc63bb04/library/alloc/src/vec/mod.rs:2771:9
6: my-project:submodule::submodule-2:my_awesome_function # <-- our function!
at ./src/subfolder-1/subfolder-2/foo.rs:67842:583
6: my-project::main # <-- function that called our function!
at ./src/main.rs:4:26
7: core::ops::function::FnOnce::call_once
at /rustc/25ef9e3d85d934b27d9dada2f9dd52b1dc63bb04/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.Aha - now we get a full overview of which functions were called before ending up at the line that produced the panic! This can be quite useful in production, but keep in mind that with everything extra, it also incurs additional performance cost you may or may not want to pay.
Listening for panics :: panic::set_hook
As seen before, when a panic occurs, we get some default behaviour compiled into our program, which prints out the panic message, and the backtrace, if RUST_BACKTRACE is set. However, Rust offers us a way to customize this behaviour by way of the std::panic::set_hook function. This function takes a closure, which’ll get executed when a panic is raised:
fn main() {
std::panic::set_hook(Box::new(|_| {
println!("A panic occurred!");
}));
panic!("Uh oh!");
}$ cargo run
A panic occurred!Setting a custom panic hook is quite cool, but one could wonder: Why would I use this, since the default panic hook is quite handy already? The main reason is for improved observability.
For example, the tracing-panic crate integrates panics into the tracing ecosystem by turning them into well-formatted tracing events:
fn main() {
// ... `tracing` setup ...
std::panic::set_hook(Box::new(tracing_panic::panic_hook));
panic!("I'm panicking!");
}$ cargo run
2024-04-23T19:22:42.351731Z ERROR tracing_panic: A panic occurred
panic payload="I'm panicking!"
panic.location="tracing-panic/src/main.rs:16:5"
panic.backtrace=disabledThis is very nice as now we can treat our panics just like the rest of our debug logs and warnings/errors in our observability tools!
Catching panics :: catch_unwind
panics are interesting as their primary purpose is to halt execution of a thread when something goes awry - however, there is a way to recover from a panic, by using std::panic::catch_unwind. This function takes in a closure, and will turn any panic that was raised inside into a Result::Err variant, which it returns as its result:
fn main() {
let result = std::panic::catch_unwind(|| {
panic!("oh no!");
});
println!("Result: {result:?}");
}$ cargo run
thread 'main' panicked at src/main.rs:3:5:
oh no!
Result: Err(Any { .. })While this function exists, it’s really not advisable to use it for applications, as:
- Recoverable errors should be handled using the
Resulttype - coming up next! - It might not catch all
panics, so debugging issues around it becomes quite difficult
Remember: panics almost always signal a bug in the code, so they should be fixed, not caught!
Recoverable Errors :: Result<T, E>
After acquainting ourselves with panics, now it’s time to get into the real deal: how do recoverable errors work in Rust, and how do they help us writing maintainable, clean and performant code while being less prone to bugs?
Recoverable Errors In Other Languages
Before revealing the answer, let’s briefly take a look at how other languages implement this behaviour.
C++
As seen earlier, C++ implements structured exception handling with the use of the throw and try/catch keywords. To signal that something went wrong, you can throw <val>, and catch it using try/catch somewhere up the call chain. However, there are some problems:
- We cannot know for sure whether a function throws (
noexceptis not mandatory, and is just a hint for the compiler), - We don’t know what kinds of exceptions a function can throw (a feature enabling this has been deprecated),
- If we miss a
try/catchsomewhere, our program can crash, - It can be inconvenient to work with
try/catchin some instances, especially when we want to have shared and custom logic mix in the success and failure cases, as it disrupts regular control flow (my C++ teacher in uni always said thatthrowis just a glorifiedgoto).
Java
Java, being influenced heavily by C++ also implements structured exception handling, but learned from its predecessor’s mistakes in a few areas. For instance, the only objects that can be thrown must implement the Throwable interface, that enables to get the error message, cause and stacktrace of the exception.
However, the biggest change in this area is the introduction of checked exceptions, which are descendants of the Exception class. If a method throws a checked exception, then it must state it in its method signature as follows:
class Parser {
public void processFile(String filePath) throws IOException, ParseException;
}When someone calls a function that can throw a checked exception, it must either:
- Handle those kinds of exceptions using
try/catch, - Let the error bubble up by introducing the same exceptions in its own
throwsclause.
This is good as it forces developers to think about specific error cases that can go wrong, which can lead to less unexpected things happening or blowing up when expected things go wrong. However, this can all be sidestepped by the other kind of exception Java provides, which are descendants of the RuntimeException class - these exceptions don’t have to be declared nor handled explicitly, which can lead to silent bugs in the code. The most notorious instance of this is the NullPointerException, an exception every Java dev has probably seen at least hundreds of times.
Unfortunately, many programmers find Java’s checked exceptions quite annoying to work with, which meant a general shift towards using runtime exceptions (for example, the Spring ecosystem’s exceptions are runtime exceptions), which offer less clarity about a function’s failure modes.
Go
One of Go’s goals is to be a very simple language, and that translates to its error handling mechanism as well. Instead of custom control flow operations handling errors, they are treated as regular function return values, thanks to the fact that we can return tuples really easily. Thus, most fallible functions in Go look like this:
func Parse(file string) (int32, error) {
data, err := ReadFile(file)
if err != nil {
return 0, fmt.Errorf("Couldn't read file: %w", err)
}
number, err := strconv.ParseInt(data, 10, 32)
if err != nil {
return 0, fmt.Errorf("Failed to parse number: %w", err)
}
return int32(number), nil
}Where the return value is a tuple of the success (int32) and failure error cases. To handle the error, the return value is then checked:
result, err := Parse("input.txt")
if err != nil {
fmt.Println("An error occurred", err)
}
// Do something with `result`However, this explicitness can get quite messy when we want to bubble up errors, since we need to do it manually each time:
func Process(file string) (int32, error) {
result, err := Parse(file)
if err != nil {
return err
}
// Process file contents
}What’s more interesting, is that on the throwing side, nothing is stopping us from making a mistake when throwing the error, like returning nil, nil, or both some data and an error - probably linters or a thorough code review can catch this, but it’d be nice if it was statically enforced by the compiler as well (subtle foreshadowing…).
The Result<T, E> Type
After seeing how other languages do it, it’s finally time to see Rust’s solution. The trick to clean, scalable error handling, is that there is no trick! We’re just leveraging the powerful enum mechanism the language provides:
enum Result<T, E> {
Ok(T),
Err(E),
}Going into why Rust has these kinds of enums is another article in itself, but long story short, this functionality is borrowed from functional languages (like OCaml, which is the language the creator of Rust liked and even built the first Rust compiler in), where these so-called sum types are used all the time. For example, the error type in Haskell is defined as:
Either a b = Left a | Right bThis is quite desirable, as it means that if you know how Rust enums work, you’ll understand how to:
- “Throw” an error in a function (just
return Err(...))), - Deal with functions that potentially return an error (just use pattern matching).
fn main() {
println!("Start!");
match std::fs::read_to_string("file.txt") {
Ok(contents) => println!("{contents}"),
Err(e) => println!("Failed to read file, cause: {e}"),
}
println!("Done!");
}$ cargo run
Start!
Failed to read file, cause: No such file or directory (os error 2)
Done!Of course, the devil lies in the details, and there are a few more considerations to make in order to achieve an easy-to-use, scalable and helpful error handling strategy in your application. We’ll explore how to do it in the next chapters by:
- Examining exactly what our error type
Eshould be defining a function, - Building a robust way of reporting errors to the users and operators of the system.
Returning Errors - What Should E Be?
Defining the error type of a fallible function is no easy task - this is where the error handling strategy can go quite wrong in a project. If not thought about properly, we can easily get into a situation where our error types are too generic, not useful to work with, or don’t compose well with other errors, which leads to developers trying to work around the different error types, not to mention headaches when debugging a production issue.
Since software development is an iterative process, instead of trying to get it right the first time, it’s best to refine things as we go along - I’d recommend this for the implementation of fallible functions as well, and Rust helps us out a great deal here: because of it’s very strict compiler, we can be sure that our refactorings won’t cause unwanted behaviour in most cases! Let’s imitate such an iterative process on an example function:
I know I need to write a function that opens a file, reads out some data and parses it to some struct - I can write the signature:
fn parse_value_from_file(path: AsRef<Path>) -> Value;But I immediately recognize that this process can fail! So I’ll need to return a Result, as I don’t want to crash my program when something goes wrong:
fn parse_value_from_file(path: AsRef<Path>) -> Result<Value, ???>;At this point, we don’t have a good picture of the failure modes this function can produce, and we don’t want to burden ourselves with it either. We can defer the problem by just returning a very simple, but versatile type as an error, like a String:
fn parse_value_from_file(path: AsRef<Path>) -> Result<Value, String> {
...
if file_does_not_exist {
return Err(format!("File '{path}' does not exist"));
}
...
if contents_malformed {
return Err("Contents of file were malformed".to_string());
}
...
Ok(parsed_contents)
}This is very convenient, as now we have an overview of what can go wrong, and what do we want to return to the caller during each “explosion”. However, we also suspect that we’ll need to do better, as working with plain String errors is not good for programmatic processing!
At this point, we arrive at a decision point - We must decide whether we want the caller to know about the exact different failure modes, or not burden them with it, and just signal that something went awry.
If we’d like the caller to know, we can provide an enumerated error type, otherwise, we can provide an opaque error type. We’ll examine these 2 error type in the next 2 sections.
Enumerated Errors
As the name suggests, enumerated errors are implemented as an enum, where each variant describes a particular failure mode, on which the caller can match on if they so desire. Additionally, they can contain some extra information about what went wrong, which can be useful for the caller:
enum ParseValueError {
FileDoesNotExistError(PathBuf),
MalformedInputError { line: u64, col: u64 },
}With enumerated errors, it’s often good practice to store another error as a source, so that the caller has even more info about the underlying root cause. However, I’d only do this with well-known error types such as std::io::Error, not private errors that might contain too much implementation details:
enum ParseValueError {
IoError(std::io::Error),
MalformedInputError { line: u64, col: u64 },
}What Makes an Error a Good Error?
As we’ve seen just now, defining enumerated errors are pretty easy, as we just need to create an enum with the different failure modes as variants, with some metadata for each one of them. However, these errors are quite hard to work with, as they don’t offer some general functionality that we’d expect from all errors. In other languages, this is usually handled by extending from a base class (like Exception in Java or Error in JavaScript), which then provides some common features that are useful for all errors (like converting it to a String or getting the underlying root cause).
However, Rust doesn’t offer inheritance, so we need a different strategy. Thankfully, the authors of the standard library thought of this, and provided us some traits that all errors should implement in order to make them useful in any context. These are:
Display: Convert error to a textual representation that’s useful for the end user,Debug: Convert error to a textual representation that’s useful for the operator,Error: Allow our error type to be composable with other errors Let’s check these out more in detail.
Implement Display
The Display implementation enables our error (and in general, any type that implements it) to convert it to some textual representation. In case of errors, this representation should contain an error message that’s suitable to show for the end user. We can trigger the conversion in 2 ways:
- By converting it into a
Stringusingto_string:
let str = e.to_string();- By printing the error using the
{}placeholder in format strings:
println!("Something went wrong: {e}");Implementing Display is quite simple - the only method that needs a body is fmt. For enumerated errors, the Display implementation will usually consist of a match statement that’ll return a different error message based on the error variant, while potentially making use of any metadata that the variant contains for that extra context that might be useful for the user:
impl std::fmt::Display for ParseValueError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
match self {
// Not extracting the error source as we don't want to
// provide the exact details to the end user, as it might
// overwhelm them.
Self::IoError(_) => write!(f, "There was a problem when reading the input"),
// Get the exact position where the file was malformed,
// So that the user knows where they need to fix it.
Self::MalformedInputError { line, col } =>
write!(f, "The input is malformed on {line}:{col}"),
}
}
}Implement Debug
The Debug implementation is very similar to Display, in that it allows values to be converted to a textual representation. However, this representation is aimed at developers and operators of the system, and not the end users - this usually means that the Debug implementation should contain more information about an error that occurred, so that the root cause can be found more easily, resulting in shorter investigation and bugfixing time.
We can trigger the Debug implementation by using the {:?} placeholder in format strings:
println!("Something went wrong: {e:?}");Implementing Debug can be done manually, but for the most part, it’s usually implemented using a derive macro:
#[derive(Debug)]
enum ParseValueError {
...
}The code snippet above will create a Debug implementation that’ll print the:
struct/enumname,- All fields of the
struct/enumvariant, using their ownDebugimplementation (This means that we can only do#[derive(Debug)]if all fields in our type areDebug).
let err = ParseValueError::MalformedInputError { line: 42, col: 100 };
println!("{err:?}");$ cargo run
MalformedInputError { line: 42, col: 100 }Implement Error
The final trait that makes our own error type useful is std::error::Error. This trait is a “marker trait”, meaning that you don’t need to actually implement any methods, just provide an empty impl block for your error type:
impl std::error::Error for ParseValueError {}This is very useful as it enables the use of dyn pointers and references to our own error type (ex. &dyn Error), which enables interacting with the error without knowing its concrete type - the reason why this is super handy will be more obvious in the next chapter.
Let’s examine Error a bit further. Checking the trait definition, we can see the following:
trait Error: Debug + Display { ... }Meaning that we can only implement Error for our type, if it also implements Debug and Display - which is logical as we’ve seen that it’s very useful for error types to offer these kinds of textual representations!
Checking the body of the trait, we can see that there is actually a method that is available for consumers to call:
pub trait Error: Debug + Display {
fn source(&self) -> Option<&(dyn Error + 'static)> { None }
}This source method is a way to get access to the source or cause of the error, if there is any. This is a “provided method”, meaning that it offers a default implementation (which states that the error does not have a cause), which is why we didn’t have to implement it when defining the impl block for our own error type.
However, in case there is an underlying source that we can point out, it’s useful to override this method and capture this piece of information:
impl std::error::Error for ParseValueError {
fn source(&self) -> Option<&(dyn std::error::Error + 'static)> {
match self {
// The wrapped error is the source
Self::IoError(e) => Some(e),
Self::MalformedInputError { .. } => None,
}
}
}We can already see that usefulness of the Error trait in source’s signature - we can refer to the cause without knowing its concrete type! This composability is very convenient and helps us out a great deal when working with more complex code.
Recap: What Makes a Good Error Type?
We’ve covered a lot of things regarding enumerated errors, so let’s do a short recap. Here are the 4 things that an error type does in order to maximize its usefulness for us and our callers:
- Implements
Debug-#[derive(Debug)]/impl Debug for ... { ... }, - Implements
Display- withimpl Display for ... { ... }, - Implements
std::error::Error, - Optional: Adds a
sourceimplementation to establish a cause chain.
This is a lot of boilerplate for each error type we define! Is there some way that we could do better?
Macros to the Rescue, a.k.a the thiserror Crate
Rust’s solution for getting rid of boilerplate lies in its powerful macro system, as it allows us to generate code based on declarative instructions. For making our lives easier when defining error types, the thiserror crate offers a procedural derive macro, which’ll accomplish the same tasks that we did in the last section in much less code, in a much more readable way. Let’s check out an example:
// `thiserror::Error` implements `std::error::Error`
#[derive(thiserror::Error, Debug)]
enum ParseValueError {
#[error("could not open file")] // `Display` impl for this variant
IoError(
// `source` = inner error for this variant +
// `impl From<std::io::Error> for ParseValueError { ... }` +
// `impl Into<ParseValueError> for std::io::Error { ... }`
#[from] std::io::Error,
),
#[error("input is malformed at {line}:{col}")] // Supports interpolation
MalformedInputError { line: u64, col: u64 },
}From the code snippet above, we can deduce the following:
thiserror::Errorwill implementstd::error::Errorfor us, meaning that we’ll need to implementDebugandDisplayfor our type,- We implement
Debugusing the standardderivemethod, - The
Displayimpl is handled by theerrorattributes, which instructsthiserrorto generate the proper textual representations per variant, errorsupports format strings, which makes building error messages quite easy,- We can tag fields with the
fromattribute to mark the as thesourcefor the given variant, and also get a conversion from the type in question to our own error type, as seen in the comment.
The code above implements the same thing we did by hand in the previous section, with much less code and in a much more readable way! The downside to this approach however, is that procedural macros increase compile times, so you might get some longer coffee breaks when working in larger codebases.
Let’s check out a more advanced example, to see more features of thiserror:
#[derive(thiserror::Error, Debug)]
pub enum DataStoreError {
#[error("data store disconnected")]
Disconnect(#[from] std::io::Error),
#[error("the data has been redacted")]
Redaction(#[source] RedactionError),
#[error("invalid header (expected {expected:?}, found {found:?})")]
InvalidHeader { expected: String, found: String },
#[error(transparent)] // delegate `source` + `Display` to inner error
Unknown(#[from] Box<dyn std::error::Error>),
}
// How to construct each variant:
let disconnect_error: DataStoreError = some_io_error.into();
// ^ DataStoreError::Disconnect(...)
let redaction_error = DataStoreError::Redaction(RedactionError { ... });
// ^ DataStoreError::Redaction(...)
let invalid_header_error = DataStoreError::InvalidHeader { ... };
// ^ DateStoreError::InvalidHeader { ... }
let unknown_error: DataStoreError = some_opaque_boxed_error.into();
// ^ DataStoreError::Unknown(...)Let’s see what happened here:
- We have 4 error variants, and our standard
Debugimplementation, - The
Disconnectvariant has astd::io::Error, which is also itssource, and it can be constructed from astd::io::Errorinstance using conversion methods (into/from), Redactionhas aRedactionErroras asource, but it doesn’t have conversion methods fromRedactionError,InvalidHeaderuses theDebugimplementation of the fields that it contains for itsDisplayimplementation,UnknowndelegatessourceandDisplayto the underlying error - since it’s a pointer to astd::error::Error, it offers these 2 functionalities, so this works without issues!
Now let’s see how we can work with these errors when implementing a function that can return one:
fn save_entity(entity: Entity) -> Result<EntityWithId, DataStoreError> {
let connection = match db::connect() {
Ok(c) => c,
// No need for `DataStoreError::Disconnect(e)`!
// `std::io::Error` -> `DataStoreError::Disconnect` is handled by `into`
Err(e) => return Err(e.into()),
};
let inserted_entity = match connection.insert(entity) {
Ok(inserted_entity) => inserted_entity,
// No need for `DataStoreError::Unknown(Box::new(e))`!
// `Box<dyn std::error::Error>` -> `DataStoreError::Unknown` is handled by `into`
Err(e) => return Err((Box::new(e) as Box<dyn std::error::Error>).into()),
};
Ok(deserialize_inserted_entity(inserted_entity))
}Alright, this code looks pretty nice, though we can’t help but notice the amount of repetition that we’ve had to write (thankfully some of it is abstracted away when we’ve used into instead of converting the types manually) - those match statements seem a bit excessive, and remind me of Go’s error handling mechanisms. Thankfully, the creators of Rust noticed this as well, and came up with a very convenient solution, which is one of my favourite features of the language to date.
This construct is the ? operator, which is essentially syntactic sugar for what we’ve done manually above.
fn fallible() -> Result<(), std::io::Error> {
let contents = std::fs::read_to_string("file.txt")?;
...
}It’s available in functions returning Results (and also Options, but we’ll focus on Result), and essentially performs the following operation at the point where we’ve inserted it: return Err(e.into<E>());. The beauty of it is that it doesn’t do any magic, just combines existing language features in a clever way that reduces error handling boilerplate significantly:
fn save_entity(entity: Entity) -> Result<EntityWithId, DataStoreError> {
let connection = db::connect()?; // `std::io::Error` -> `DataStoreError::Disconnect`
let inserted_entity = connection.insert(entity)
// `Box<dyn std::error::Error>` -> `DataStoreError::Unknown`
.map_err(|e| DataStoreError::Unknown(Box::new(e)))?;
Ok(deserialize_inserted_entity(inserted_entity))
}The beauty of it lies in the into<E> call that happens internally, as users don’t have to explicitly convert their error types to match up with the function signature - if there is a viable conversion available, ? will take advantage of it! This also works cases where we don’t need to convert to a different type, as all types can be converted to themselves, meaning that for all types T, the following impl is auto-generated by Rust:
impl From<T> for T { fn from(t: T) -> Self { t } }This functionality is a prime example of how the proper combination of basic building blocks lead to something greater than the sum of its parts. We’ll see more examples of the ? operator in the upcoming sections and chapters.
Opaque Errors
While enumerated errors are good at conveying information about what exactly went wrong, there are cases where we don’t want this behaviour, and just let the caller know that an error occurred during the execution of the fallible function. Some reasons for this include:
- There are too many failure modes to keep track of in an
enum- burden for caller tomatchon them, - We don’t want to leak implementation details of the function to callers.
As we’ve seen before, the way to achieve in Rust this is by using an opaque error type, a type that signals that something is an error without revealing its concrete type. This is exactly what was happening in std::error::Error::source - it just returns some kind of pointer of type dyn std::error::Error!
The simplest way to achieve this is to use Box<dyn std::error::Error>. It’s a unique pointer to some object that implements std::error::Error. The reason why we need a pointer is that trait objects are !Sized, meaning that they don’t have a defined size (since error types can have varying sizes), so we can’t place them on the stack. However, pointers have a known size, so we must work with them to facilitate accessing these errors of unknown concrete types.
Callers have a bit less freedom when working with an opaque error, as they can only perform operations using dynamic dispatch exposed by std::error::Error - as we’ve seen before, this consists of:
- Fetching the user-facing textual representation (
Display::display/to_string), - Fetching the operator-facing textual representation (
Debug::debug), - Getting the source of the error (
Error::source).
Let’s try returning an opaque error from a function! To make it a bit easier, we’ll make use of the following conversion that is implemented by the standard library:
impl From<impl std::error::Error> for Box<dyn std::error::Error> { ... }Meaning that we can convert any error type implementing Error into a pointer to something that implements Error - quite convenient! This means that if we use Result<T, Box<dyn Error>> in our function signature, we can just use the ? operators to propagate all errors opaquely to our callers:
fn read_config_file() -> Result<serde_json::Value, Box<dyn std::error::Error>> {
// Turn `std::io::Error` into `Box<dyn Error>`
let contents = std::fs::read_to_string("cfg.json")?;
// Turn `serde_json::Error` into `Box<dyn Error>`
let parsed_contents = serde_json::from_str(&contents)?;
Ok(parsed_contents)
}This approach works, but it has some drawbacks, namely that:
- The error type is quite a mouthful (albeit we could define a type alias for it),
- We still need define a custom type if there’s no underlying error to propagate,
- We cannot attach extra context to why each error can occur, which could help the user understand better what went wrong.
Ergonomic Opaque Errors a.k.a the anyhow Crate
We could implement a custom opaque error type that solves the problems outlined above, but thankfully the work has already been done in the anyhow crate, which defines the anyhow::Error type, which is an opaque error type on steroids - we’ll see why in this section. To make our lives even easier, it also provides a type alias for Results that return anyhow::Error as their error type:
type anyhow::Result<T> = Result<T, anyhow::Error>;Let’s see what we can do with anyhow::Error.
First of all, it defines a conversion to anyhow::Error from types implementing std::error::Error, so that we can use the ? operator quite liberally (just like with Box<dyn Error>):
fn read_config_file() -> anyhow::Result<serde_json::Value> {
// `impl std::error::Error` -> `anyhow::Error`
let contents = std::fs::read_to_string("cfg.json")?;
// `impl std::error::Error` -> `anyhow::Error`
let parsed_contents = serde_json::from_str(&contents)?;
Ok(parsed_contents)
}It also allows us to attach context to our errors using the context/with_context extension trait methods (be sure to import anyhow::Context!):
use anyhow::Context;
fn read_config_file() -> anyhow::Result<serde_json::Value> {
let contents = std::fs::read_to_string("cfg.json")
.context("Failed to read config file")?;
let parsed_contents = serde_json::from_str(&contents)
.with_context(|| format!("Failed to parse config from {contents}"))?;
Ok(parsed_contents)
}This does 2 things:
- It converts our underlying error to an
anyhow::Error, - Saves the context that we provide in the parameter, which’ll be printed when using
Debugprinting or using the{:#}formatter.
Another useful feature provided by anyhow are the anyhow::anyhow! and anyhow::bail! macros, which allow creating ad-hoc errors without defining a custom error type:
fn validate_password(user_id: &str, password_hash: &str) -> anyhow::Result<()> {
let password_hash_from_db: String = ...;
// Probably not a good idea in production apps...
if (password_hash_from_db.len() != password_hash.len()) {
// `anyhow!` macro for ad-hoc error definition
return Err(anyhow::anyhow!("Password size doesn't match!"));
}
...
if (&password_hash_from_db != password_hash) {
// shorthand: `bail!(...) = return Err(anyhow::anyhow!(...))`
anyhow::bail!("Passwords don't match!");
}
Ok(())
}As you can see above bail! is just a shorthand for returning the ad-hoc error from the current function immediately, saving us from typing return Err(anyhow!(...)).
Now that we’re acquainted with anyhow, let’s see how it implements Display and Debug for anyhow::Error:
use anyhow::Context;
fn read_config_file() -> anyhow::Result<serde_json::Value> {
let contents = std::fs::read_to_string("cfg.json")
.context("Failed to read config file")?;
let parsed_contents = serde_json::from_str(&contents)
.with_context(|| format!("Failed to parse config from {contents}"))?;
Ok(parsed_contents)
}
fn main() {
let err = read_config_file().context("Failed to initialize config").unwrap_err();
println!("{res}");
println!("==========");
println!("{res:?}");
}$ cargo run
Failed to initialize config
==========
Failed to initialize config
Caused by:
0: Failed to read config file
1: The system cannot find the file specified. (os error 2)
Stack backtrace:
...As you can see, the Display implementation will just print the top-most context or error message that we passed in when converting to or creating an anyhow::Error instance - perfectly useful for user-facing messages. The Debug representation has some more details - namely the cause chain, which are the textual representations of underlying errors and contexts that were added to this error before printed. It also prints a stack backtrace (if RUST_BACKTRACE is set), which is very useful for debugging production issues.
eyre
As we’ve seen just now, anyhow provides pretty nice error reporting - but what if you don’t like it or want to customize it? anyhow itself doesn’t provide a way to achieve this; and that’s why a fork called eyre was created, which extends anyhow with support for customizable error reporters called Handlers. In addition, it also exposes its own terminology, which is a little different from anyhow:
anyhow::Error/anyhow::Result→eyre::Report/eyre::ResultContext/context/with_context→WrapErr/wrap_err/wrap_err_with
But don’t worry - anyhow’s public types and traits are also re-exported as is, to make eyre be a drop-in replacement for anyhow.
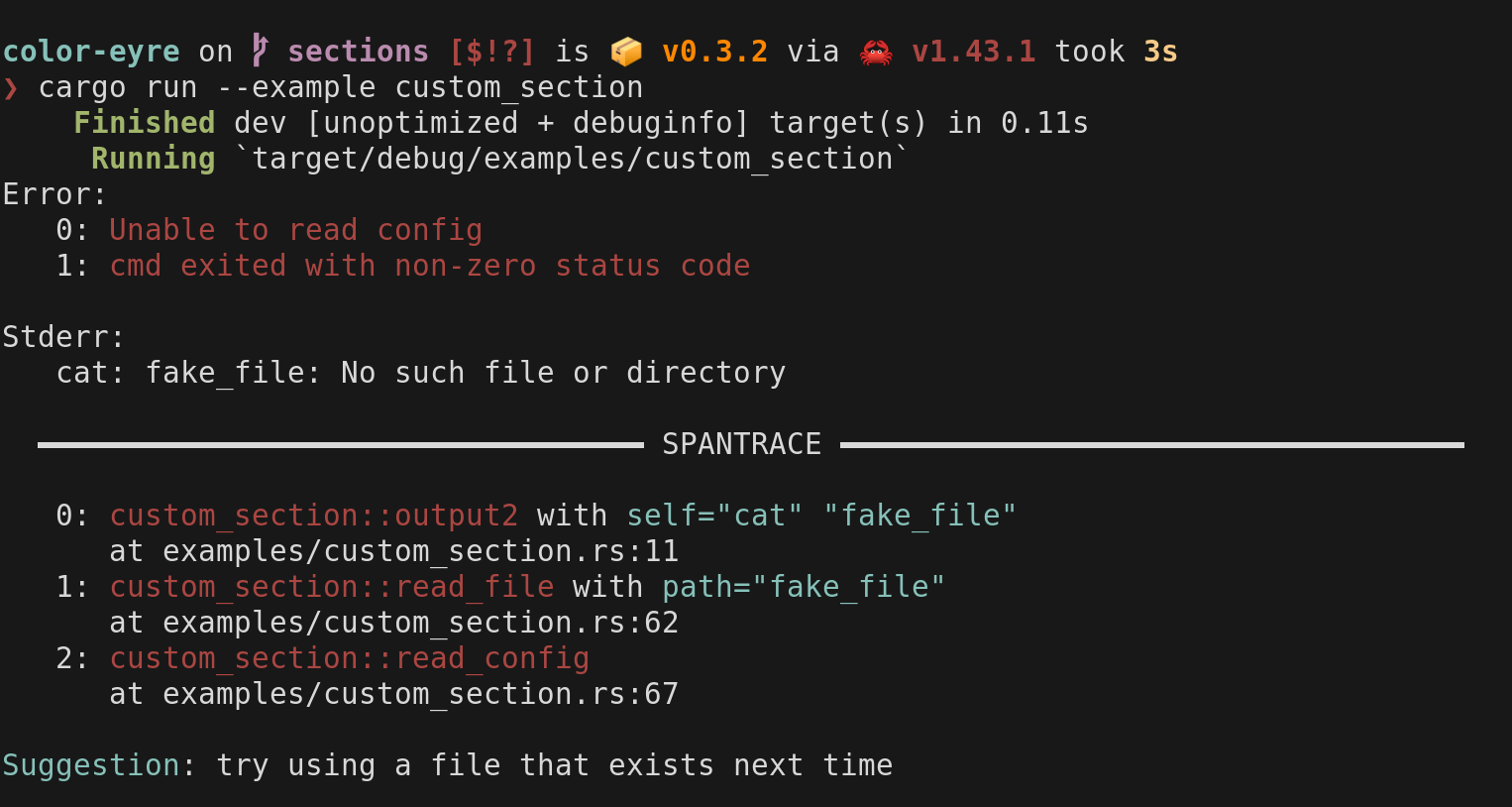
While you could definitely write your own Handler, it’s first best to try one that already exists. The most widespread available is color-eyre, which implements a Handler that’s very similar to anyhow, but is more colourful, and thus more pleasant to read:
Combination of Enumerated + Opaque Errors
Before moving on to the next chapter, let’s see one final example that ties in everything that we learned in this one. More often than not, it’s beneficial to combine enumerated and opaque errors in some way, when only a partial differentiation between failure modes is required. Take a look at the code snippet below:
#[derive(thiserror::Error, Debug)]
enum RegisterUserError {
#[error("{0}")]
ValidationError(ValidationError),
#[error(transparent)] // wrap anything unexpected as an `anyhow::Error`
UnexpectedError(#[from] anyhow::Error),
}
fn validate_user(user_data: &UserData) -> Result<(), ValidationError> { ... }
fn register_user(user_data: UserData) -> Result<(), RegisterUserError> {
let validated_user = validate_user(user_data)?;
// Use `.context` to convert underlying error to `anyhow::Error` with extra context
let inserted_user = db::insert(validated_user).context("Failed to insert user")?;
...
}The RegisterUserError type is an enumerated error, which can distinguish between a concrete failure mode (ValidationError), and an opaque failure mode (UnexpectedError) for representing other things going wrong. This pattern of offering one or more concrete failure mode(s) and a “catch-all” Unexpected variant is something that you can see in many projects written in Rust. Also, notice how the ? operator helps us out when dealing with different fallible functions, making the error handling logic quite clean so that we can focus on the business logic inside our functions!
Reporting Errors - With Minimal Noise
Now that we’ve learned about how to create, compose and handle errors in our functions, it’s time to dive into error reporting, which is the art of displaying errors in user interfaces and logs in the most straightforward way possible, so that the message is clear for end users and operators alike.
A good rule of thumb to remember is to always report errors for operators in a single place, in order to minimize noise that they need to sort through, which can cause delays when investigating a high-severity production incident. The place for reporting the error should always be where the error is handled, and not where it’s propagated, meaning that the following piece of code is flawed:
fn fallible() -> anyhow::Result<Value> {
...
let val = foo().map_err(|e| {
tracing::error!("Error occurred: {e:?}"; // ❌ Reporting + propagation
e
}))?;
...
}The problem with this is that e can be potentially logged more than once. First time in the map_err, and then later on by some other error handling logic that we might not even be aware of.
A good practice to perform instead of this is to add extra context to the error on propagation:
fn fallible() -> anyhow::Result<Value> {
...
let val = foo().context("Failed to perform foo")?; // ✅ Adding extra context
...
}This way, when the error finally gets reported, the error reported can print all relevant context, resulting in clean error logs! This pattern is also desirable as it allows developers to add context more than once in functions propagating an error from a deep call stack, also contributing to clean and informative error logs for operators.
Let’s implement error reporting in different applications! We’ll try this in a CLI and HTTP backend server, which are types of projects that are being written more and more in Rust.
In CLIs
The trick to CLI error reporting is to remember that the main function can not only return (), but also a Result<(), E>, where E implements std::error::Error - in this case during a failure, the program will print the error’s Debug representation to stderr, and return an exit code of 1. Based on this, the recipe is quite simple:
- Just return
anyhow::Result<()>(or some other generic error type) frommain, - Use
?to propagate up errors from downstream functions, - Add a
contextto each fallible function, so the user knows in what context the error occurred!
Let’s see this in action:
use anyhow::Context;
fn main() -> anyhow::Result<()> {
let config_file = read_config_file().context("Failed to initialize config")?;
let command = parse_command().context("Failed to parse command")?;
let output = match command {
Command::Foo => perform_foo(...).context("Failed to execute command foo")?,
Command::Bar => perform_bar(...).context("Failed to execute command bar")?,
};
cleanup(output).context("Failed during cleanup")?;
Ok(())
}$ cargo run
Error: Failed to initialize config
Caused by:
0: Failed to read config file from "./config.toml"
1: The system cannot find the file specified. (os error 2)While in the previous chapter, we mentioned that the Debug representation is mainly targeted towards operators, using it as the main error reporter is fine for CLIs, as the cause chain can be useful for end users during most cases. If this is not the case for your application, feel free to choose a different strategy for error reporting that makes sense for your application’s needs.
In HTTP Servers
The error reporting objective in HTTP servers is similar to that of CLIs, but a bit more involved. Here, the main goal is to provide a single error handler which:
- Transforms errors to HTTP responses,
- Produces a log message with more detailed information for operators.
Before diving into the details, it’s important to mention that this area is still in development. Quoting Luca Palmieri:
“None of the major Rust web frameworks have a great error reporting story, according to my personal definition of great.”
I recommend following his work on Pavex, where he promises a robust, correct and easy-to-use error handling solution.
As for using a web framework that’s available today, the steps for implementing an error reporter is as follows:
- Propagate errors up to the request handler using
?, - Implement a conversion:
YourErrorType -> HttpResponsefor defining what should the server return in case of an error, - Log the error or let the framework do it for you (this depends on the framework of choice).
For the example, we’ll be using actix, but it can be adapted to other frameworks. It’ll be a bit involved, so we’ll take it step-by-step.
HTTP Servers :: actix Example - Server & Endpoint Setup
The first step is to configure our server instance and register our endpoint(s). For logging, we’ll make use of tracing-actix-web crate that interfaces with tracing. tracing is not in context for this blog post, but in a nutshell, it provides a structured logging mechanism for great observability in Rust applications.
async fn register(user: Json<UserRequest>) -> Result<HttpResponse, RegisterUserError> {
let validated_user = validate_user_request(user)?; // <- Propagate validation error
let inserted_user = db::insert(validated_user)
.await
.context("Failed to insert user in DB")?; // <- Propagate DB error
Ok(HttpResponse::Ok().json(inserted_user))
}
#[tokio::main]
async fn main() -> anyhow::Result<()> {
init_tracing();
HttpServer::new(move || {
App::new()
.wrap(TracingLogger::default()) // <- Add logging middlewre
.route("/users", web::post().to(register))
})
.bind("127.0.0.1:8080")?
.run()
.await?;
Ok(())
}In the snippet above, we achieve multiple things. First, we implement our register endpoint. Don’t worry about RegisterUserError, we’ll see how it looks later. We use the ? operator to propagate errors from downstream fallible functions.
In main, we set up tracing, initialize an actix server, add the TracingLogger middleware, and register our endpoint. Finally, we bind the server to our desired address, and start it so it can listen to incoming requests.
HTTP Servers :: actix Example - Error Setup
Next, let’s check out RegisterUserError in more detail. We use what we learned before regarding combining enumerated and opaque errors:
#[derive(thiserror::Error, Debug)]
enum RegisterUserError {
#[error("Failed to validate incoming request")]
ValidationError(ValidationError),
#[error(transparent)]
UnexpectedError(#[from] anyhow::Error),
}Remember: the from directive for UnexpectedError is the reason why we can just use the ? operator for any downstream error - here we make use of it for propagating the DB error that can happen when inserting the user into the database.
Next up, we need to define a mapping for our error type, so actix knows what HTTP response code and body it should return for each variant:
#[derive(serde::Serialize)]
struct ErrorResponseBody {
pub message: &'static str,
}
impl ResponseError for RegisterUserError {
fn status_code(&self) -> StatusCode {
match self { // Define what status code each error variant should map to
Self::ValidationError(_) => StatusCode::BAD_REQUEST,
Self::UnexpectedError(_) => StatusCode::INTERNAL_SERVER_ERROR,
}
}
fn error_response(&self) -> HttpResponse {
let mut builder = HttpResponse::build(self.status_code());
match self { // Define the body of each error variant
Self::ValidationError(v) => builder.json(v),
Self::UnexpectedError(_) => builder.json(ErrorResponseBody {
message: "An unexpected error occurred!",
}),
}
}
}Since we’re exposing a JSON-formatted API, we’ll just use actix’s HttpResponseBuilder::json method to create an error JSON response. With this in place, actix will automatically convert our RegisterUserError instances into the proper HTTP responses during runtime! Let’s try it while we’re at it:
HTTP Servers :: actix Example - Validation Error
First, let’s see what we’ll get when the caller of our API encounters a validation error.
Response Code: 400 Bad Request
Response Body:
{
"message": "User is invalid",
"fields": [{ "name": "email", "issue": "'foo' does not contain a @" }]
}Trace:
WARN HTTP request{
...
exception.message=Failed to validate incoming request
exception.details=ValidationError(ValidationError {
message: "User is invalid",
fields: [ValidationErrorField { name: "email", issue: "'foo' does not contain a @"}]
})
...
}You can see that both the end user and operator get sufficient information!
Note: The formatting of the tracing log message is the default one, which is readable for humans but hard to ingest into a telemetry provider.
tracingcan be configured to output its messages in different formats, which is out of scope of this article.
HTTP Servers :: actix Example - Unexpected Error
Now let’s see what happens when our production DB instance is down, while the caller tries to register a user:
Response Code: 500 Internal Server Error
Response Body:
{ "message": "An unexpected error occurred!" }Trace:
ERROR HTTP request{
...
exception.message=Failed to insert user in DB
exception.details=UnexpectedError(Failed to insert user in DB
Caused by:
Could not connect to DB
)
...
}Here we can see that the error message is much more vague for our end user (which is good as we don’t want to expose internal information about our system), while containing all necessary information for our operator, who can identify the root cause of the issue quickly thanks to this!
Based on this example, you should be to adapt your own HTTP server application with whatever framework you’re using to have a production-ready error reporting mechanism in place.
Bits & Bobs
After examining how to define, handle and report errors, I’d like to share some random facts and useful tips that might come in handy while working on a Rust codebase.
Result<T, E> Is #[must_use]
The Result type is marked as #[must_use], meaning that if you discard one, the compiler will emit a warning:
fn fallible() -> anyhow::Result<()> { ... }
fn main() {
// warning: unused `Result` that must be used
// = note: this `Result` may be an `Err` variant, which should be handled
fallible();
}The compiler is being your friend here by highlighting discarded Results, as they should always be handled in a production-ready application. Handling in this context can mean different things:
- Either propagate the error to the caller:
fallible()?;, - Or unwrap it with a note:
fallible().expect("fallible should never fail as ...");. Only do this in case it’s a bug if theResultcontains anErrvariant, - Explicitly discard the
Result:let _ = fallible();This is useful as it explicitly marks that we’re not interested in the outcome of some operation. You’ll see this pattern most often when sending messages on a channel, wheresendreturnsErrif nobody is listening anymore:
let _ = tx.send(42); // `tx` is the Sender side of a channelResult<Result<T, E1>, E2> a.k.a. Double Trouble
In some cases, it might be worthwhile to return a nested Result type if you want to force the caller to handle the different kinds of errors separately. In the example below, we decompose the different failure modes by returning a Result with a std::io::Error, and then an inner result with a serde_json::Error.
fn read_config_file() -> Result<Result<serde_json::Value, serde_json::Error>, std::io::Error> {
let contents = std::fs::read_to_string("cfg.json")?;
let parse_result = serde_json::from_str(&contents);
Ok(parse_result)
}Handling the error can be achieved in a few different ways, see below:
fn main() -> anyhow::Result<()> {
// Don't differentiate between errors, just propagate both
let value = read_config_file()??;
let value = read_config_file()
.context("Failed to read config file")? // Add context for outer error
.context("Failed to parse config file")?; // Add context for inner eror
let value = read_config_file()
.unwrap_or(Ok(serde_json::Value::Null))?; // handle outer error differently from inner
Ok(())
}Keep in Mind the Error Size
Finally, you should keep in mind the size of your error types - since Results are allocated on the stack in most cases, they should not have a large memory footprint. If you know that your error type or some variants of it can get quite large, it’s better to introduce indirection by Boxing it.
A good example of this practice is serde_json::Error:
pub struct Error {
// The actual error is stored on the heap,
// so `Error` is the same size as a pointer
err: Box<ErrorImpl>,
}
struct ErrorImpl {
code: ErrorCode,
line: usize,
column: usize,
}
pub(crate) enum ErrorCode {
Message(Box<str>),
Io(io::Error),
EofWhileParsingList,
...
}The Future
To close out this already not so short article, let’s take a look at some things that are in the pipeline to be stabilized in future versions of Rust, which will make error handling even easier.
try Blocks
try blocks will allow users to use the ? operator without creating a new function - it’ll be useful if no new function is necessary, but would like to enjoy the benefits of the ?.
#![feature(try_blocks)]
fn foo(num_str_1: &str, num_str_2: &str) -> i32 {
let result: Result<i32, std::num::ParseIntError> = try {
num_str_1.parse::<i32>()? + num_str_2.parse::<i32>()?
};
result.unwrap_or(42)
}Tracking issue: https://github.com/rust-lang/rust/issues/31436.
std::error::Error::sources
The sources function provides us with an iterator that traverses all sources recursively using Error::source. The first element of the iterator is the error object on which we’re invoking sources. We can use this to implement an anyhhow-like cause chain representation:
#![feature(error_iter)]
impl std::fmt::Debug for ParseValueError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
writeln!(f, "{}", self)?;
// skip the first element as it's just `self`
for source in self.sources().skip(1) {
writeln!(f, "Caused by:\n\t{source}")?;
}
Ok(())
}
}Tracking issue: https://github.com/rust-lang/rust/issues/58520.
Homework
And that’s it! Remember, this was just scratching the surface of the Rust error handling story, as there is still so much to dive into. Here are some of my recommendations of what to look into next:
- Watch Decrusting the tracing crate by Jon Gjengset to learn more about
tracing, - Read
std::error,thiserror,anyhow,eyredocs (read Rust docs in general, they are very informative and high quality), - Check what error types your favourite crate defines to have more intuition of what error types to define in your own code,
- Check out error handling examples for HTTP frameworks:
- Play around with defining and handling errors when working in Rust!
- Don’t forget to have fun!
Summary
As this article was quite long, I’d like to provide a summary with the most important takeaways:
- A
panicis 99% a bug in the code! - Use
Result<T, E>for recoverable errors: Remember enumerated vs. opaque error types, - The
?operator is Rust’s superpower for clean error handling - it translates to:return Err(e.into<E>()), - Have a single location in your app where the error:
- Gets logged,
- Is converted to a user-facing representation.
References
Docs: std, tracing-panic, thiserror, anyhow, eyre
try_blocks chapter from The Rust Unstable Book
matklad (2020). Study of std::io::Error
Palmieri, Luca (2024). Rust web frameworks have subpar error reporting
Gjgengset, Jon (2022). Rust for Rustaceans. No Starch Press.
Palmieri, Luca (2022). Zero to Production in Rust.